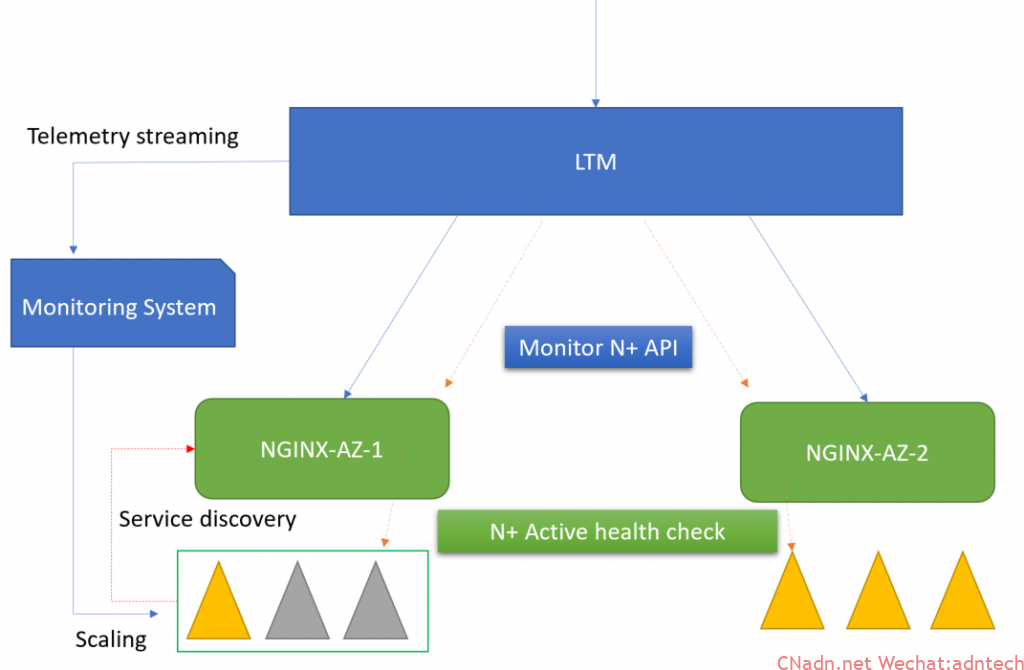
场景
LTM给NGINX做LB是一种较为典型的双层负载均衡,也就是典型的L4.L7分离的双层负载均衡方案。
在这样的架构下,如果多个NGINX背后所负载的server是一致的话,并不会出现不同的NGINX所面对的server可用数量不同情况。
但是,如果LTM的pool member中的NGINX是位于不同的可用区或者不同的DC,此时LTM如仅做应用层负载均衡或仅monitor nginx本身,那么LTM是无法感知到 NGINX 背后(upstream)到底有多少可用的业务服务器。如果某个 NGINX 的upstream中可用服务器已经很少,此时LTM会依旧分配同等数量的连接请求给该NGINX,会导致该 NGINX 后的服务器过载,从而降低服务质量。
思路
如果我们能够让LTM感知到NGINX的upstream中当前有多少可用的服务器,并设置一个阀值,如低于该可用数量则LTM不再向该NGINX实例分配连接。这样就可以较好的避免上述问题。运维人员可根据LTM报出的日志或 Telemetry Streaming输出,及时触发相关自动化流程对该NGINX下的服务实例进行快速扩容,当可用服务实例数量恢复大于阀值后,LTM则又开始向该NGINX分配新的连接。
NGINX Plus本身提供了一个API endpoint,通过获取该API并做相应处理即可获得可用的服务器实例数量,在LTM上则可以利用external monitor实施对该API的自动化监控与处理。
方案
1. 获取的API资源路径是: http://your-domain.com/api/6/http/upstreams/your-upstream-name/?fields=peers
注:api后的版本6可能会因nginx plus的版本不同而不同.
2.返回的内容示例如下,我们主要关心state: up, 只要获取到总的state: up数量即可
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
{ "peers": [ { "id": 0, "server": "10.0.0.1:8080", "name": "10.0.0.1:8080", "backup": false, "weight": 1, "state": "up", "active": 0, "requests": 3468, "header_time": 778, "response_time": 778, "responses": { "1xx": 0, "2xx": 3435, "3xx": 6, "4xx": 20, "5xx": 4, "total": 3465 }, "sent": 1511086, "received": 99693373, "fails": 0, "unavail": 0, "health_checks": { "checks": 1754, "fails": 0, "unhealthy": 0, "last_passed": true }, "downtime": 0, "selected": "2020-01-03T07:52:57Z" }, { "id": 1, "server": "10.0.0.1:8081", "name": "10.0.0.1:8081", "backup": true, "weight": 1, "state": "unhealthy", "active": 0, "requests": 0, "responses": { "1xx": 0, "2xx": 0, "3xx": 0, "4xx": 0, "5xx": 0, "total": 0 }, "sent": 0, "received": 0, "fails": 0, "unavail": 0, "health_checks": { "checks": 1759, "fails": 1759, "unhealthy": 1, "last_passed": false }, "downtime": 17588406, "downstart": "2020-01-03T03:00:00.427Z" } ] } |
3. 因此可以编写如下python脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#!/usr/bin/python # -*- coding: UTF-8 -*- import sys import urllib2 import json def get_nginxapi(url): ct_headers = {'Content-type':'application/json'} request = urllib2.Request(url,headers=ct_headers) response = urllib2.urlopen(request) html = response.read() return html api = sys.argv[3] try: data = get_nginxapi(api) data = json.loads(data) except: data = '' m = 0 lowwater = int(sys.argv[4]) try: for peer in data['peers']: state = peer['state'] if state == 'up': m = m + 1 except: m = 0 #print data['peers'][]['state'] #print m if m >= lowwater: print 'UP' |
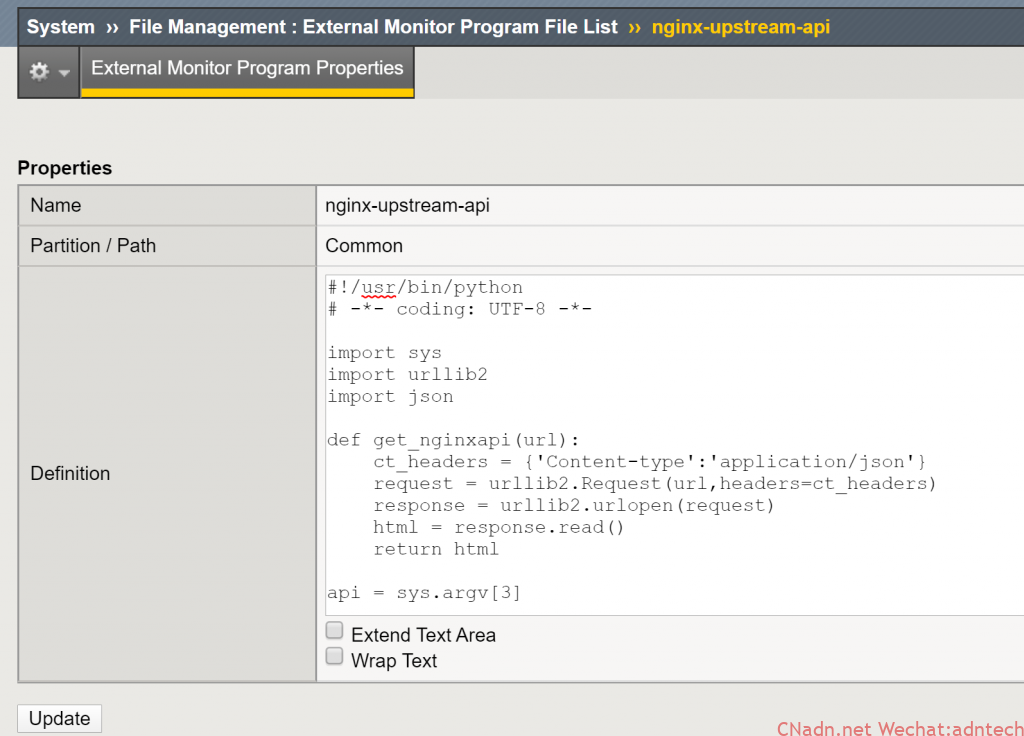
4. 将该脚本上传至LTM,上传路径:system--file management--external monitor--import, 效果如下
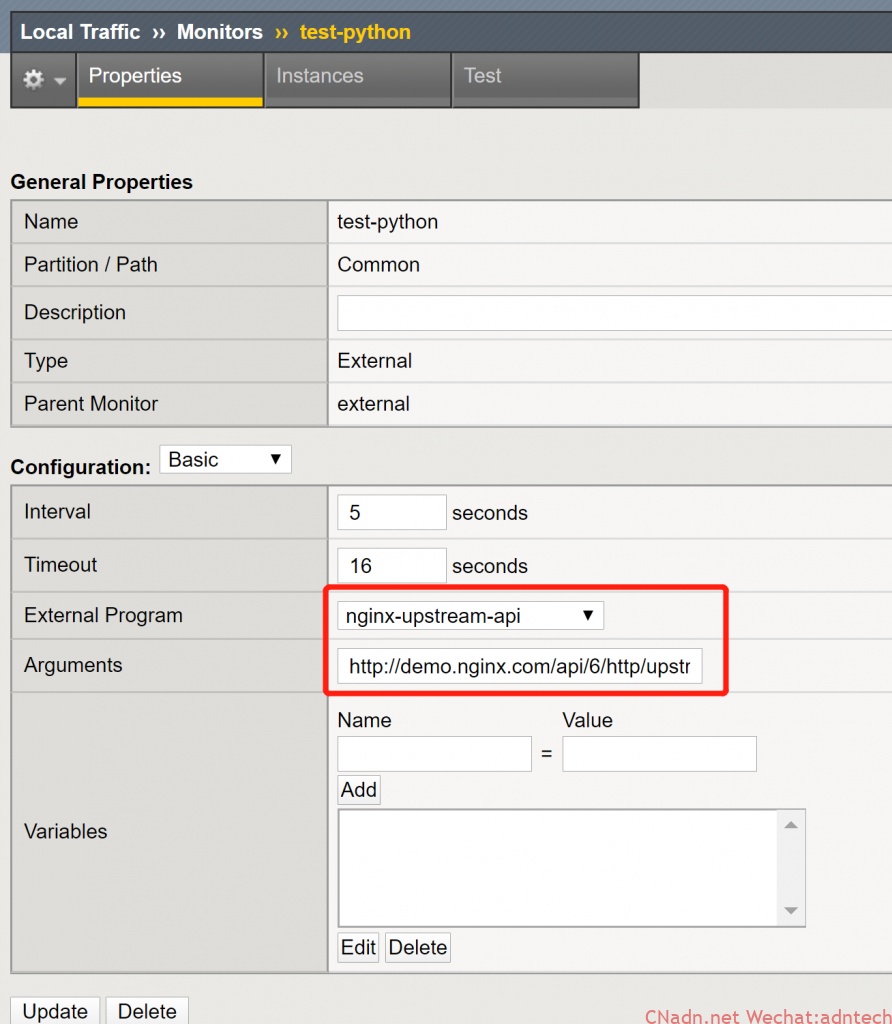
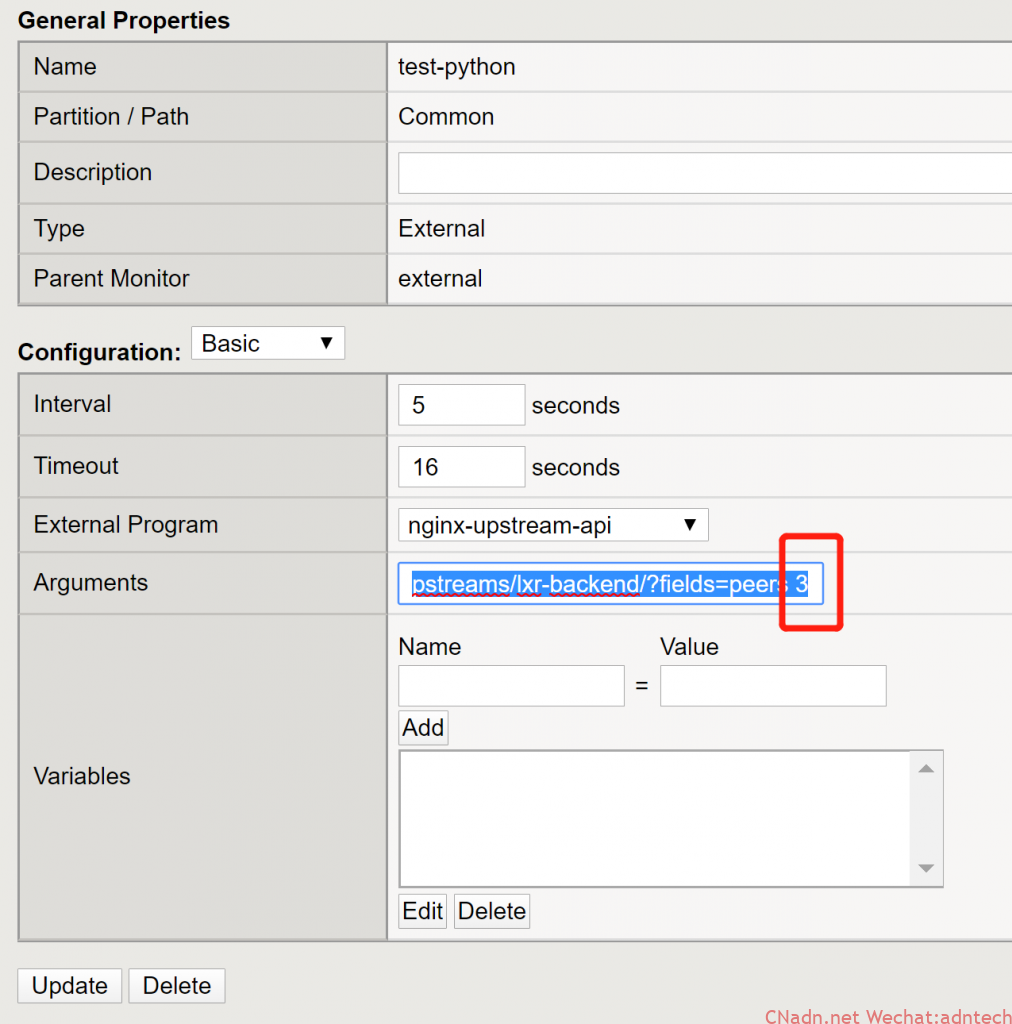
5. 配置external-monitor, 注意arguments部分填写:http://demo.nginx.com/api/6/http/upstreams/lxr-backend/?fields=peers 2
注意空格前填写的是相关API的URL,空格后填写阀值
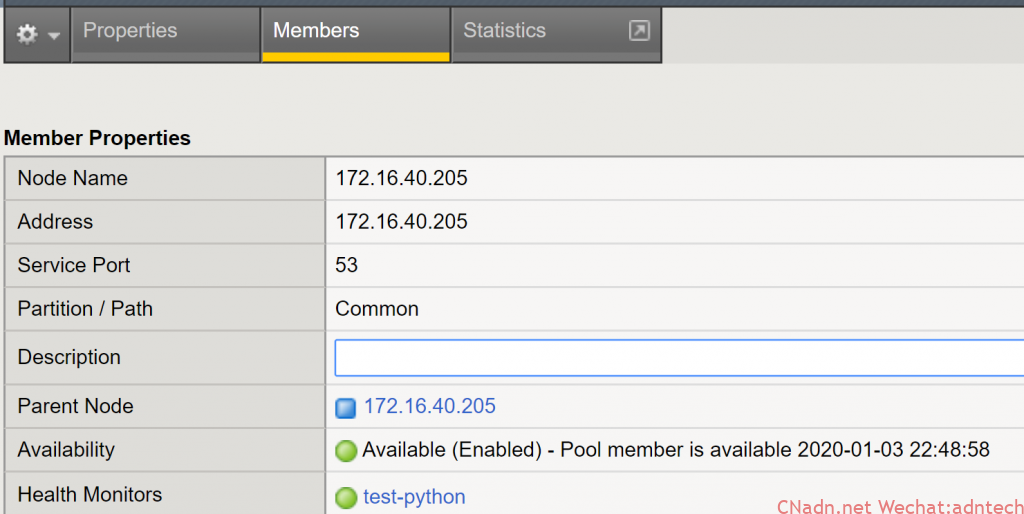
6. 随后将该monitor 关联到某个nginx pool member上
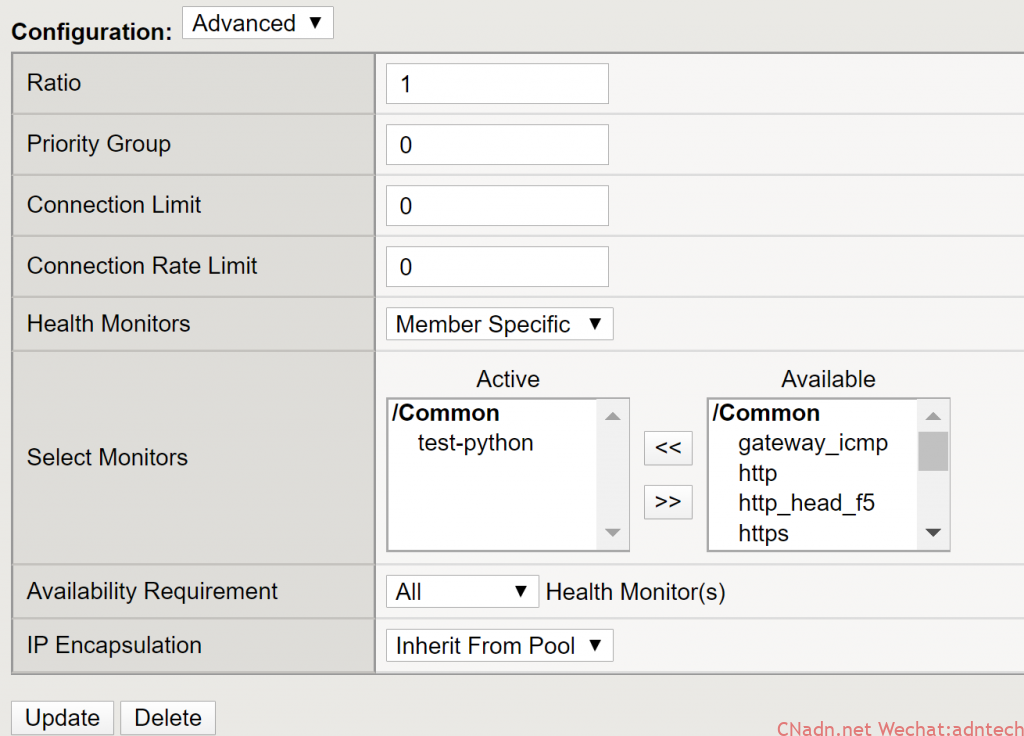
可以看到,该member 此时标记为up
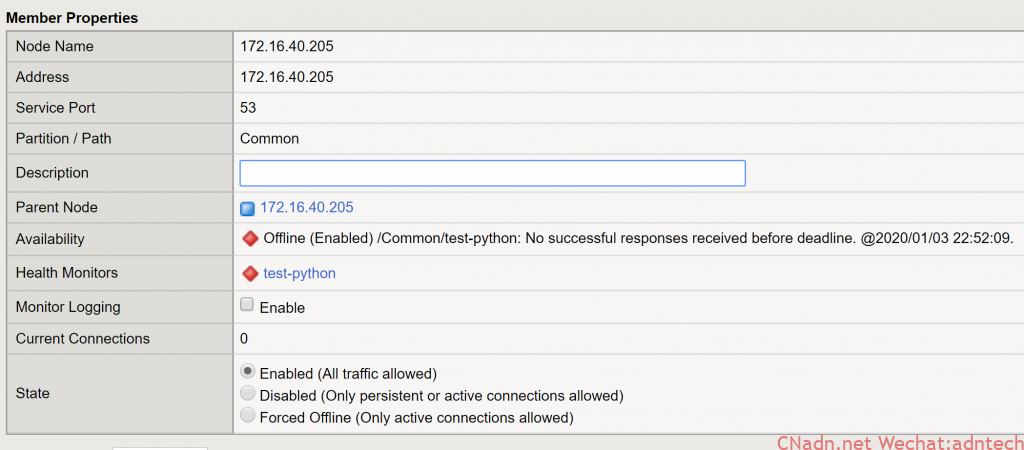
7. 如果将阀值改为3,由于当前upstream中仅有2台可用,因此LTM将标记该NGINX实例为down
其它:
•输入错误的url或者错误的endpoints 等,都直接置为down,这样用户可以比较容易发现问题
•Upstream中被设置为backup的状态的成员认为是可用的
•此方法还可以避免实际服务器被LTM和nginx两次monitor
更多思考 【感谢 廖健雄 在群里提出以下问题并讨论】
Q: 如果nginx有很多个upstream的话,LTM怎么设定?
A: 从前端ltm到nginx来说,如果此nginx后端的任何upstream容量不足的话,都不应该给这个nginx再分链接,所以多个upstream的话,可以ltm上设置多个monitor,并设置 all need up。
Q: 如果nginx的上的配置有问题,实际业务访问不了,上述方案似乎无法发现此场景问题
A:是的,对于nginx本身可用性及配置问题,可考虑在LTM上加一个穿透性的7层健康检查,但是如果NGINX本身有很多server/location段落配置,又想发现所有这些段落可能存在的问题,那就意味着要对每个服务都进行7层健康检查,这个在服务特别多场景下,需要思考,或许过度追求探测的完美性会对业务服务器带来更多的探测压力。理论上,LTM上一个穿透性检查+所有upstream的API检查,能够满足大部分场景。
Q: 在大规模NGINX部署场景下,如何降低NGINX健康检查对后端服务的压力?
A:可考虑nginx做动态服务发现app,app的可用性由注册中心类工具来解决,从分布式的健康检查变成注册中心集中式的健康检查;
或者借助NGINX plus的upstream API 通过集中健康检查系统来动态性更新upstream,这样可避免频繁reload配置, 从而减低健康检查带来的压力。



文章评论